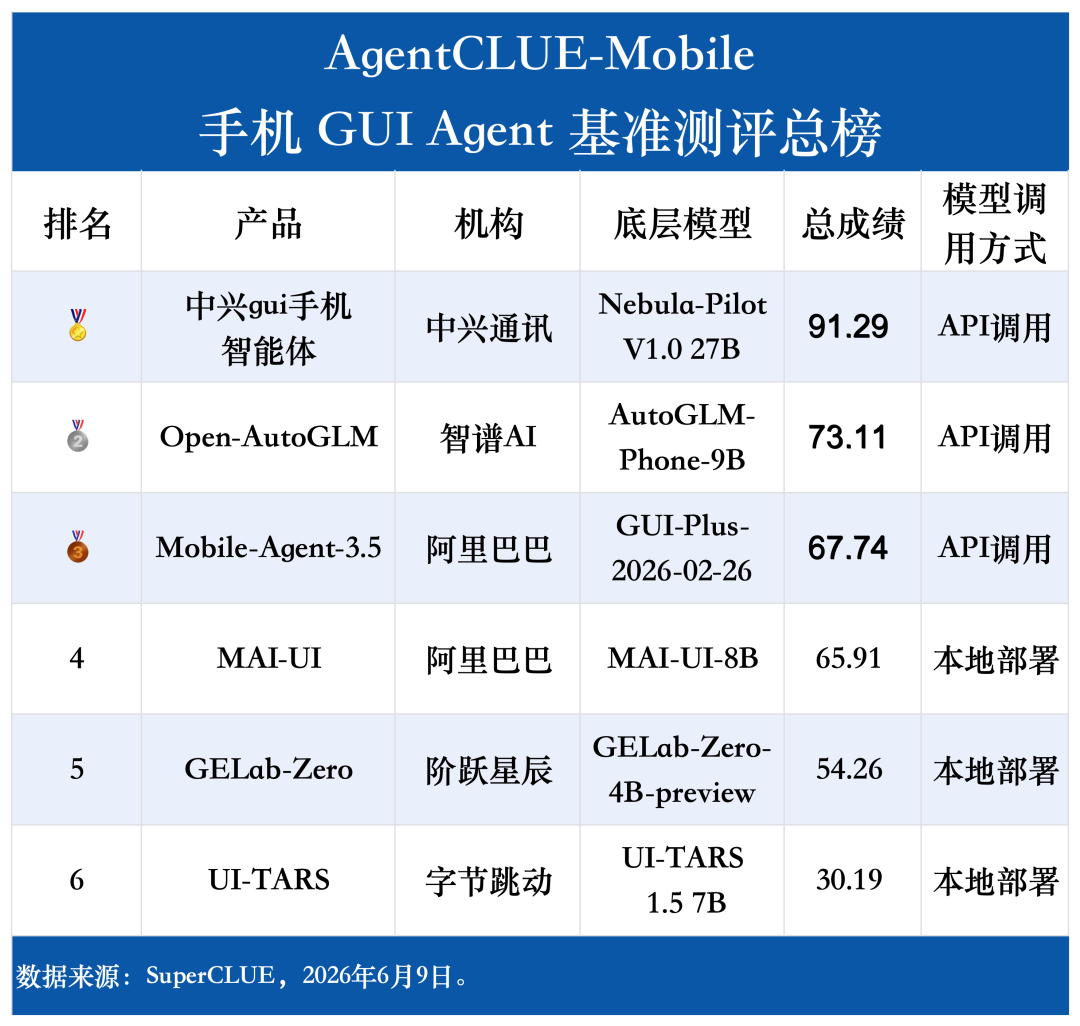
深圳新闻网2026年6月11日讯(记者 翁瑞峰)近日,第三方测评机构SuperCLUE重磅发布手机助手GUI智能体测评6月榜单,中兴gui手机智能体以91.29分的绝对优势登顶总成绩榜第一,在全部评测维度中均保持首位,展现出接近商业可用水平的端到端能力。
评测在统一ADB手机交互与纯视觉输入环境下,通过标准化任务集与评分体系,度量各Agent在意图解析、视觉感知、长链路执行任务上的决策质量。测评涵盖6款手机助手GUI智能体产品,测评对象聚焦于具有智能体架构与配套模型的产品。
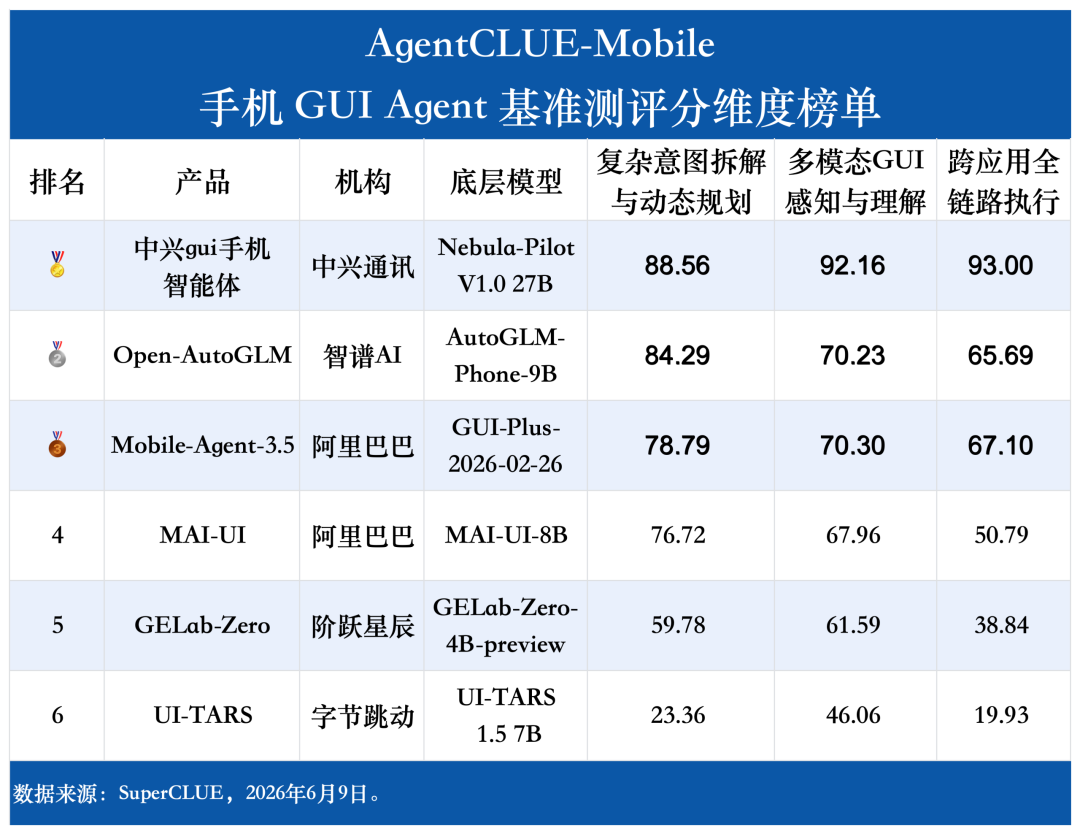
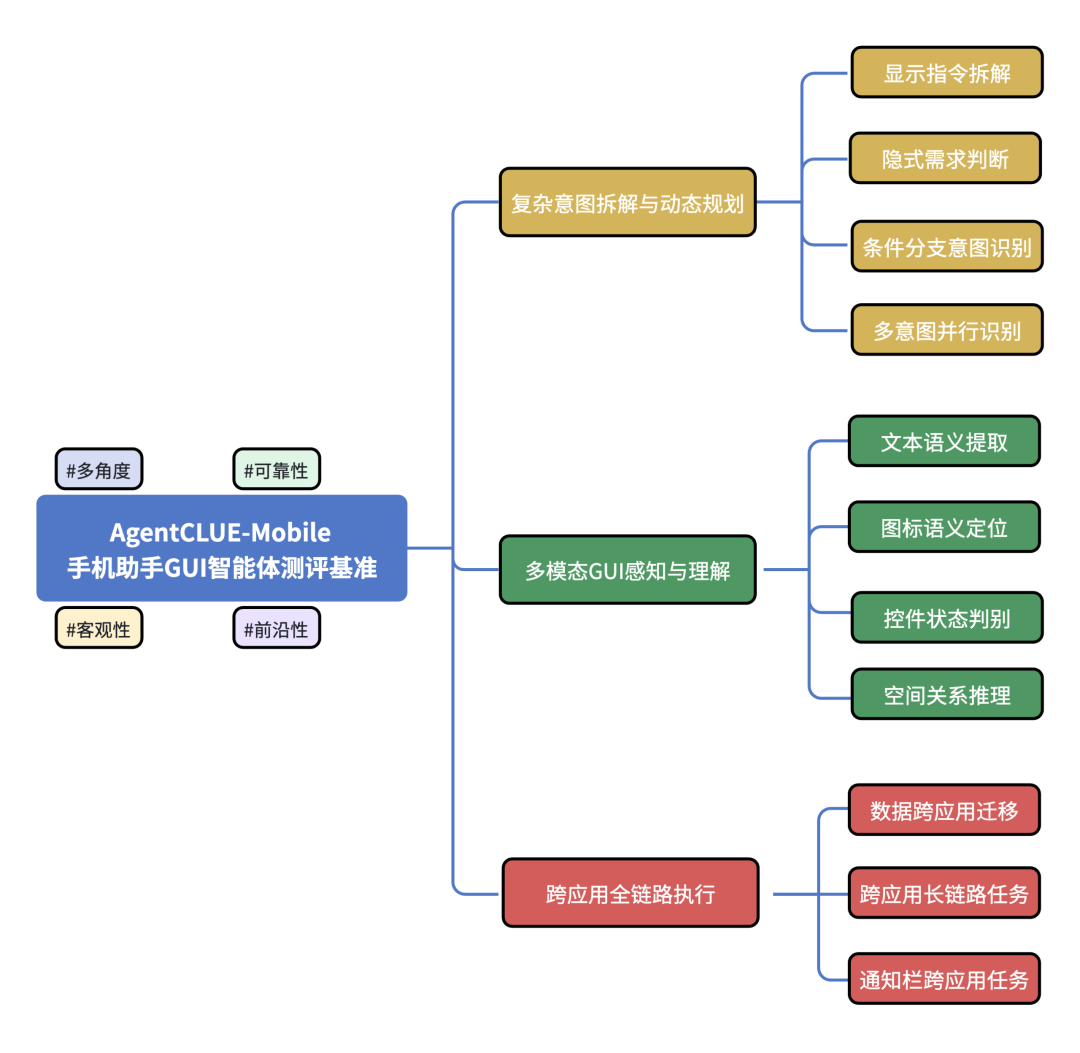
为建立公平、可量化的横向对标基准,测评机构SuperCLUE提出AgentCLUE-Mobile手机助手Agent测评场景基准。该场景基准在统一的ADB手机交互环境与纯视觉输入条件下,通过标准化任务集与可复现的评分体系,从复杂意图拆解与动态规划、多模态GUI感知与理解、跨应用全链路执行三大维度,横向度量不同Agent在意图解析、视觉感知、长链路执行及异常恢复等维度的决策质量,精准剥离系统权限与工程封装带来的性能噪声,为Agent产品迭代与技术选型提供客观依据。
其任务覆盖了用户日常手机操作的高频场景,从第三方App的内容消费、社交互动到系统底层的硬件连接与设置,构成了手机助手Agent能力的完整评测版图。
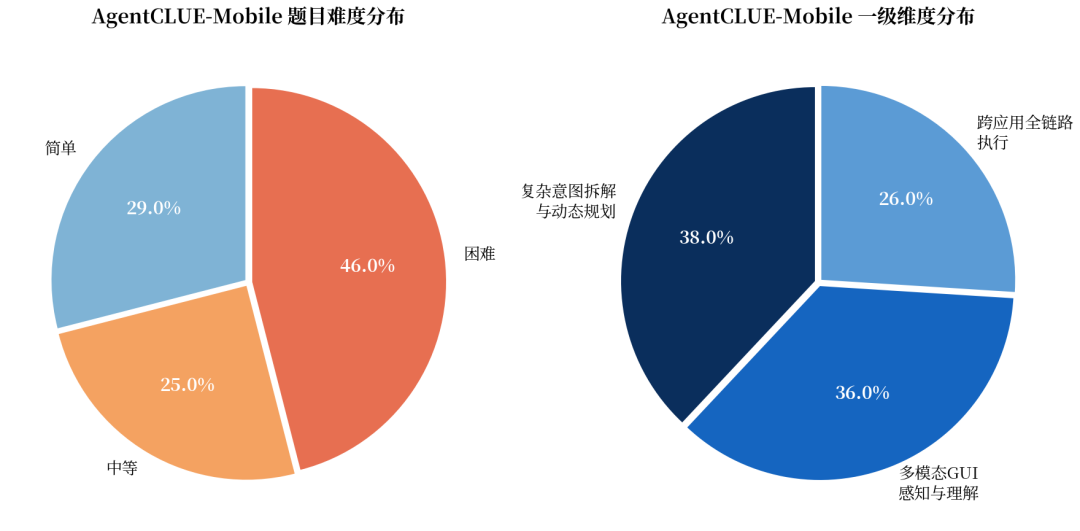
AgentCLUE-Mobile评测基准设计标准化题目,覆盖三大一级维度与三种难度层级。难度呈“倒金字塔”结构,困难题目占比最高,简单与中等次之,以高难度任务为主,旨在拉开能力差距、暴露长链路执行中的状态丢失与异常恢复短板。维度上,“复杂意图拆解与动态规划”占比最高,涵盖显式/隐式指令、多意图并行与条件分支;
“多模态GUI感知与理解”次之,覆盖文本语义、图标定位、控件状态与空间关系;“跨应用全链路执行”则聚焦数据迁移、长链路任务与通知栏跨应用场景。三大维度均衡配比,全面评估Agent的认知决策、视觉感知与执行闭环能力。
手机智能体与手机的交互方式
被评手机智能体采用“感知-决策-执行”闭环架构。用户以自然语言下发任务后,智能体基于当前屏幕截图进行视觉理解与任务规划,生成结构化动作指令(如应用启动、坐标点击、文本输入等)。
该指令经ADB传输至手机端执行,执行后的新截图回传智能体,形成“观察-决策-执行”的循环迭代,直至任务完成。整个链路中,ADB承担统一执行接口,截图承担纯视觉感知输入,智能体则负责认知决策与动态规划。
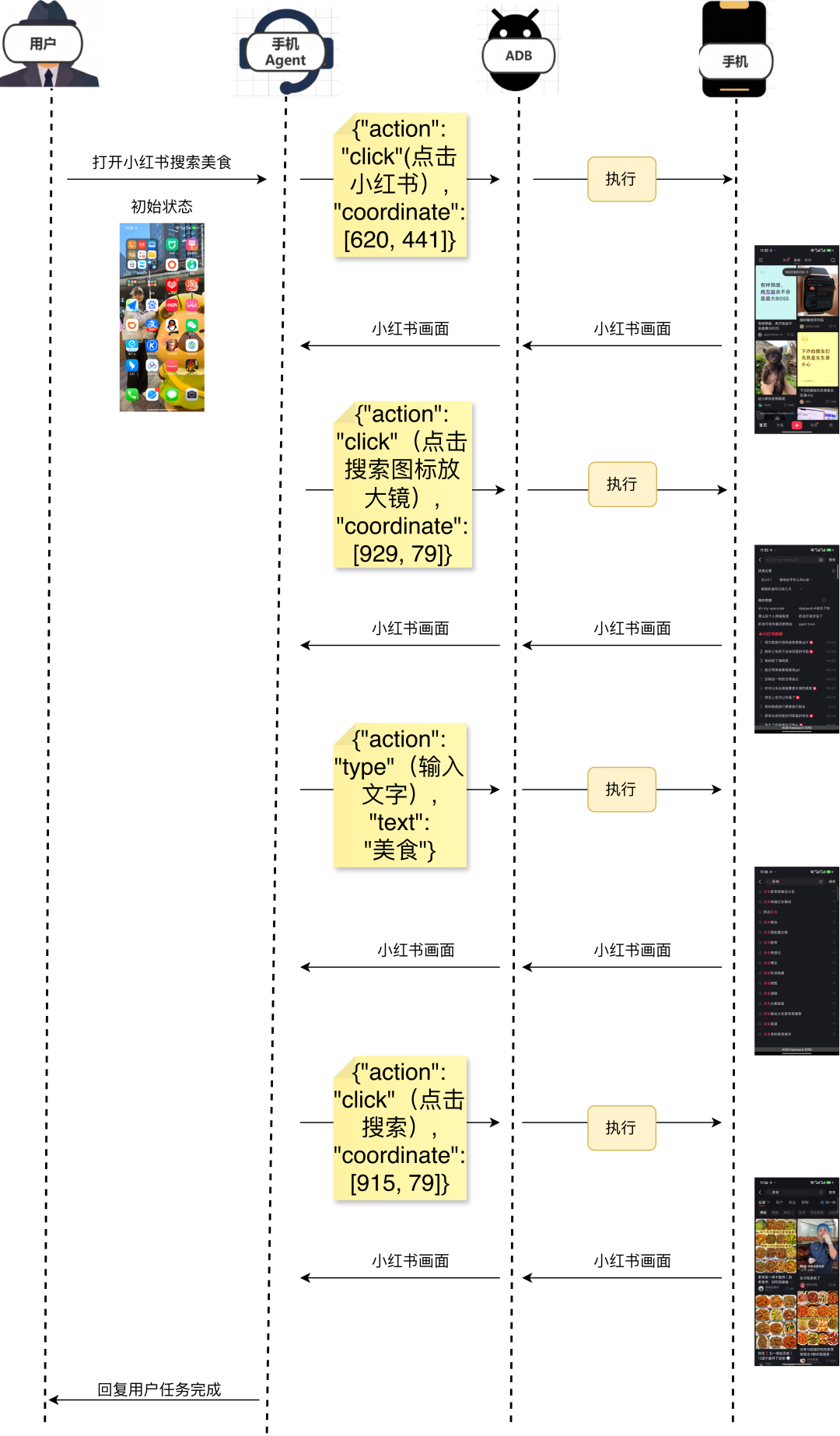 评测流程介绍
评测流程介绍
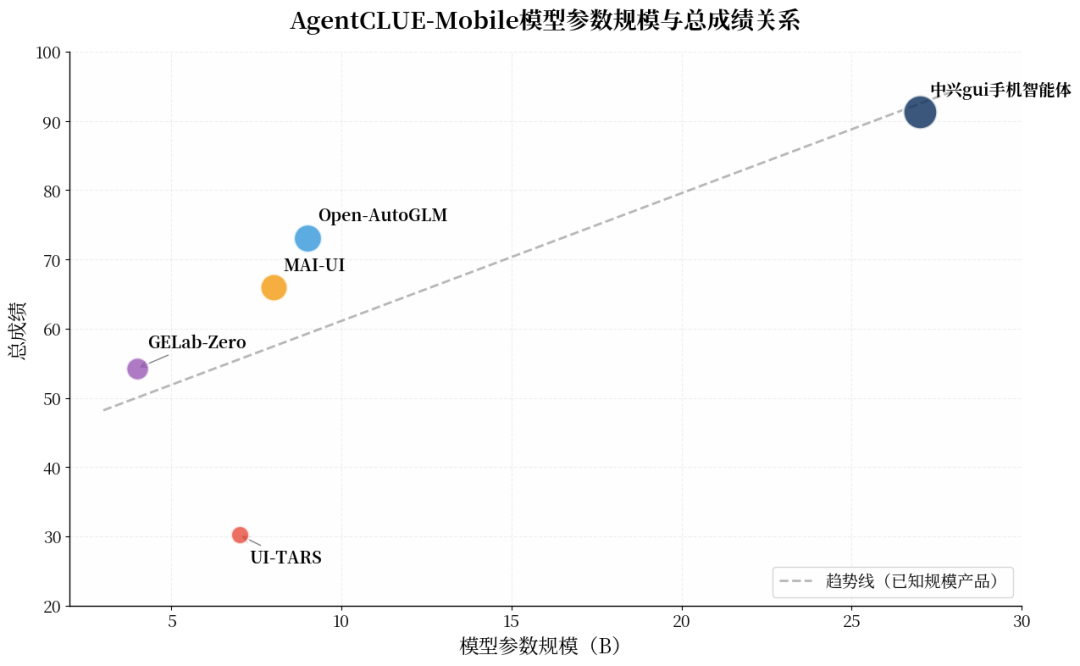
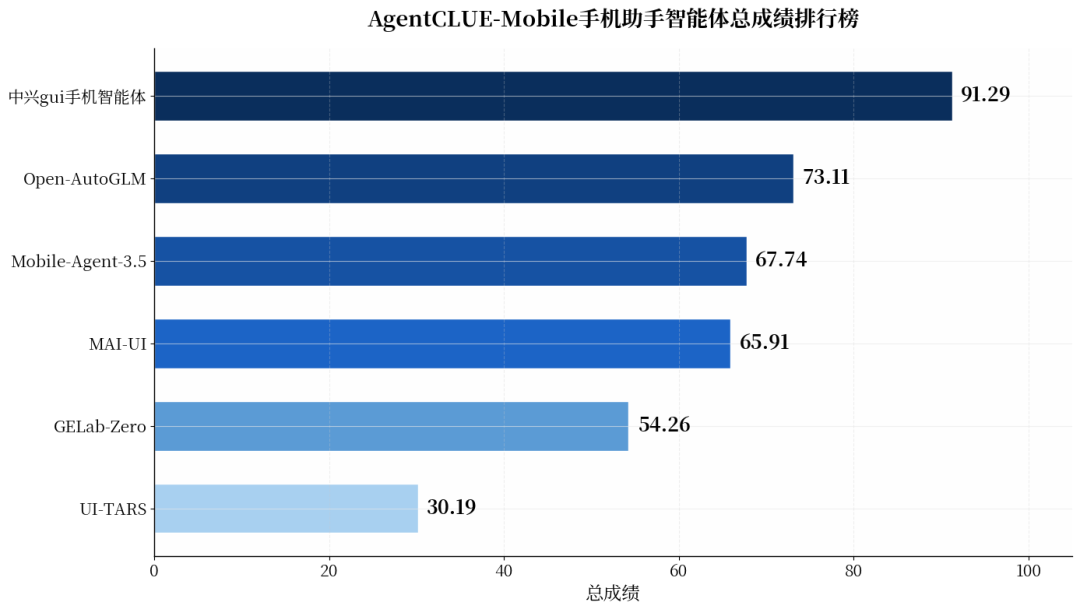
总成绩格局:一家领跑、三家胶着、两家追赶
从总成绩来看,参评产品呈现出明显的梯队分化:
第一梯队(>90分)仅中兴gui手机智能体一家,以91.29分的绝对优势领跑,在全部评测维度中均保持首位,展现出接近商业可用水平的端到端能力。
第二梯队(65-75分)Open-AutoGLM(73.11)、Mobile-Agent-3.5(67.74)、MAI-UI(65.91)形成胶着的中游集团,三者分差不足8分,但能力侧重各有不同。
第三梯队(<60分)GELab-Zero(54.26)与UI-TARS(30.19)处于追赶阶段,其中UI-TARS与榜首差距超过60分,反映出纯视觉驱动小模型在复杂手机交互场景下的能力瓶颈。
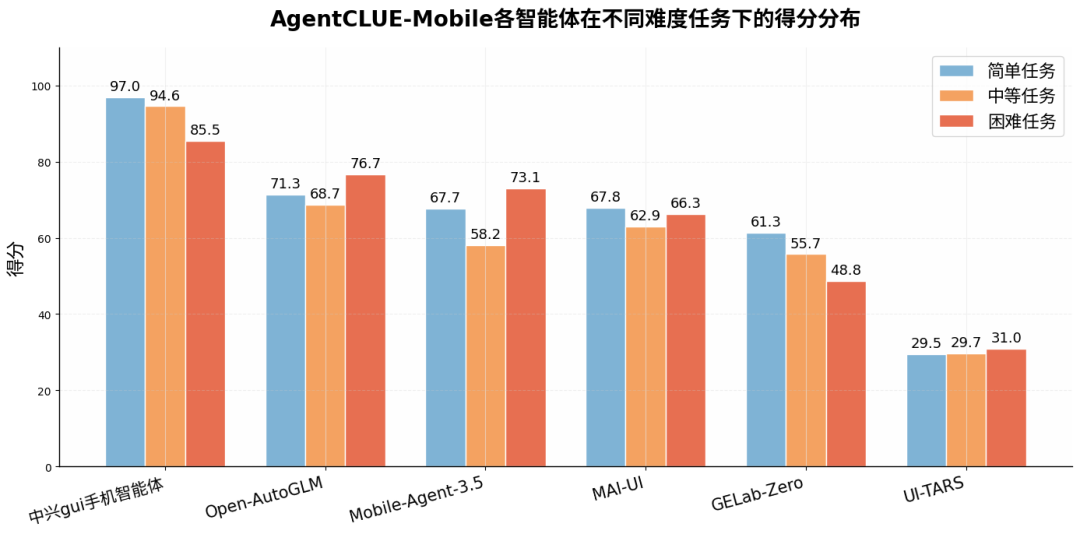
部分智能体困难任务反超中等任务的柱状图显示各智能体在三级难度下的得分变化。中兴以接近满分的简单任务(96.99)和85+的困难任务得分,实现“全难度通吃”的稳健表现。Open-AutoGLM与Mobile-Agent-3.5出现“难度逆序”:困难任务得分(76.71/73.09)反超中等任务(68.68/58.17),说明中等任务中的多意图并行与隐式判断对规划稳定性的挑战更甚于长链路困难任务。MAI-UI与GELab-Zero呈标准递减曲线但绝对值偏低;UI-TARS三档难度均止步30分左右,尚处于“全难度失效”状态。
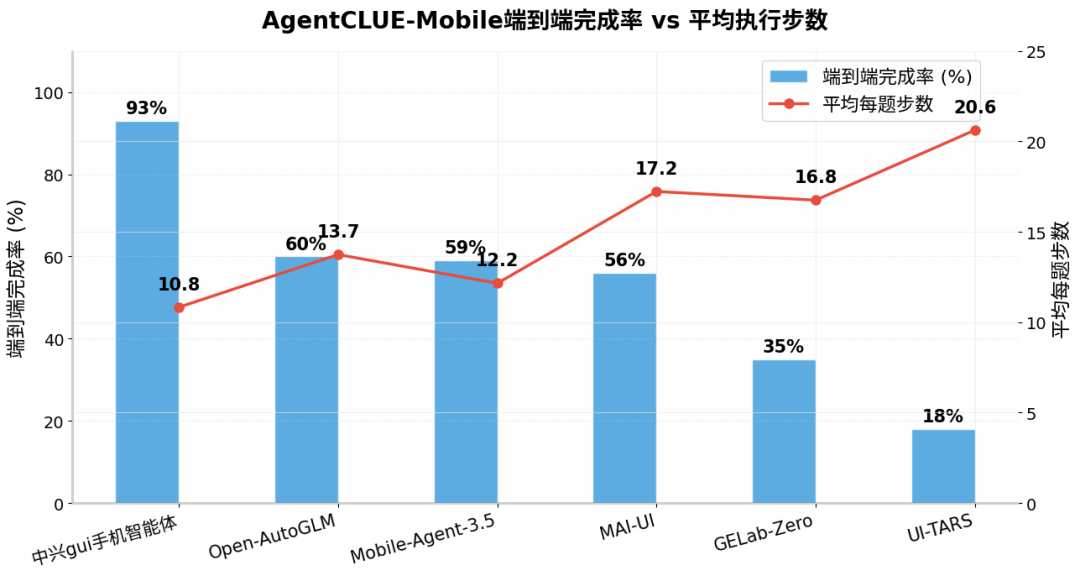
中兴gui手机智能体完成率高且步数少
该双轴图从“结果”与“过程”两个维度评估各智能体。
中兴表现最佳:完成率93%,平均每题仅10.83步,既快又准。其每一步决策质量高,极少冗余或回退,已接近商用水平。
第二梯队(完成率56%–60%,步数差异大):Open-AutoGLM(60%/13.74步)、Mobile-Agent-3.5(59%/12.15步)、MAI-UI(56%/17.23步)。其中Mobile-Agent-3.5效率均衡;MAI-UI步数最多、完成率最低,存在大量无效操作,“做得很多但做对的少”。
第三梯队:GELab-Zero(35%/16.75步)与UI-TARS(18%/20.62步)均为低完成率、高步数。UI-TARS尤为典型,平均20.62步仅换来18%成功率,每11步才成功1次,陷入“步数越多、错误越多”的困境。
整体趋势:完成率越高,步数越少(如中兴);完成率越低,步数越多(如UI-TARS)。这说明实用化瓶颈不仅在于“能否做对”,更在于“多少步能做对”。提升单步决策质量、压缩无效操作,比单纯提高单步正确率更能优化用户体验。
(测评图片由中兴及SuperCLUE提供)