深圳新闻网2026年6月15日讯(记者 刘惠敏)近日,在北京智源大会现场,围绕具身智能的技术路线之争再次成为行业焦点。过去一年,随着机器人产业快速升温,一个问题持续引发讨论:机器人究竟应该走VLA路线,还是世界模型路线?
这一问题之所以重要,是因为它直接决定了下一代机器人的技术架构与进化方向。VLA路线强调直接从视觉和语言生成动作,追求高效执行;而不少世界模型路线研究者认为,机器人首先需要建立对物理世界的理解能力,才能进一步产生可靠行为。
对此,智平方创始人兼CEO郭彦东在大会现场对这一行业争论抛出明确答案:世界模型不是VLA的竞争路线,而是VLA体系中的核心组成部分;而在世界模型与VLA融合之后,类脑架构将成为下一代机器人大脑的重要演进方向。

这一判断背后,也对应着智平方过去三年持续高压强的技术布局——从端到端VLA,到融合世界模型,再到最新发布的类脑大模型NeuroVLA,一条清晰的机器人大脑进化路线正在成型。
郭彦东指出,从生命演化的视角看,行动能力并非孤立产生,生命首先需要感知环境、理解环境,然后才会产生行动。因此,世界模型与VLA并非竞争路线,而是天然统一的整体——世界模型负责理解世界,VLA负责作用于世界。他强调,当前被广泛讨论的“世界模型”并非由物理规律驱动,而是靠海量数据训练出来的预测模型。
“数据足够多,模型就知道水杯越过桌面会下落、手机屏幕用力敲可能会碎——这不是物理规律的总结,而是大数据学习的结果。”基于这一判断,郭彦东重新定义了VLA:VLA是多模态融合的大数据驱动端到端模型架构的总称,在这个定义下,世界模型与VLA没有本质区别,更不是替代关系。如果不将世界模型融入VLA,很多复杂任务根本无法完成,例如泡茶需要先拿茶包再倒水,这依赖语言模型的推理认知;而世界模型擅长短程物理预测,如水杯靠近桌边可能掉落。只有两者合并,机器人才兼具长程任务规划与短程物理预测能力。
基于这一理念,2025年11月,智平方联合北京大学率先推出融合世界模型的新一代架构Video2Act,首次实现“先预测、后执行”的机器人模型范式,使世界模型真正成为机器人行动系统的一部分。在第三方评测中,Video2Act相较硅谷同类标杆模型取得超过30%的性能领先。2026年,由英国皇家两院院士、强化学习奠基者Pieter Abbeel等全球顶尖学者联合完成的世界模型权威综述中,Video2Act被作为“世界模型+VLA融合路线”的代表性成果重点引用,标志着技术争论正被新范式取代。
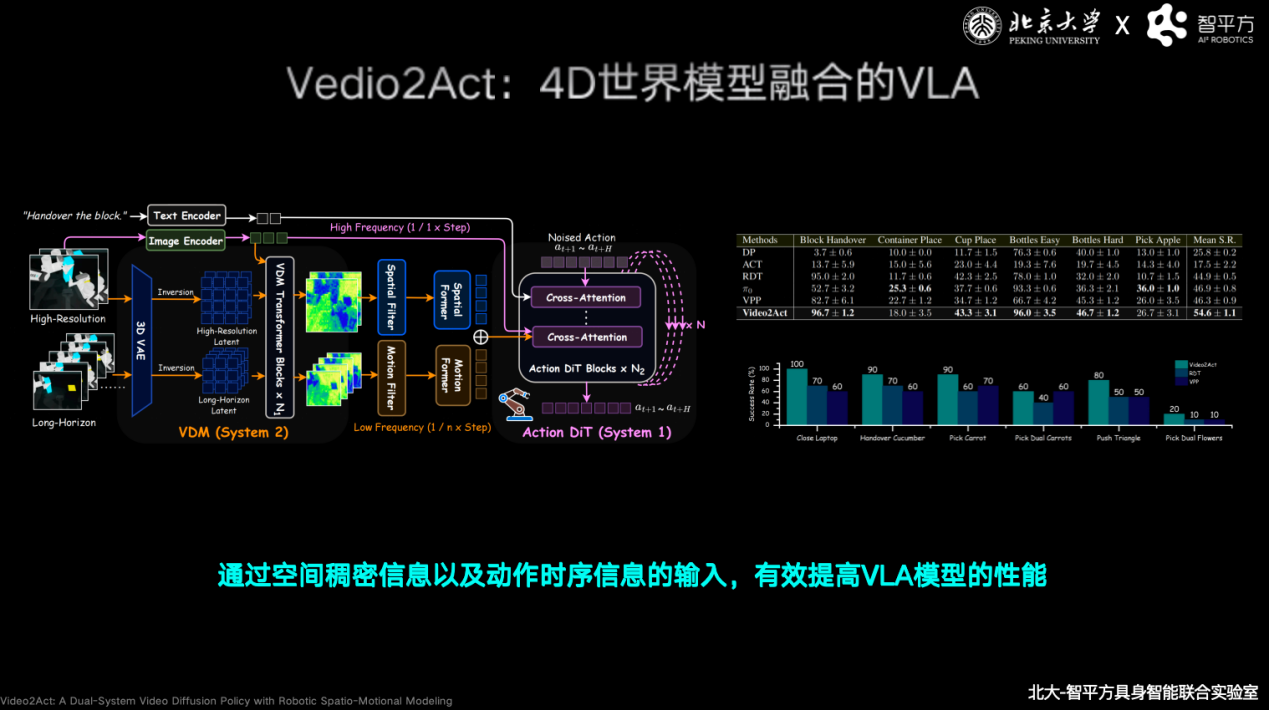
而在世界模型与VLA融合之后,郭彦东进一步指出下一代方向:类脑架构。
郭彦东在大会分享中这样说道:“大家做人形机器人,天天想着如何长得像人,但没有人想如何让脑子更像人。”现有VLA架构中,机器人虽具备较强理解能力,但面对真实世界的复杂环境,普遍存在响应慢、动作抖动、能耗高等问题。原因在于,大多数机器人仍然依赖一个统一的大模型同时处理感知、推理与控制。但在人脑中,皮层负责思考,小脑负责协调运动,脊髓负责本能反射,不同系统在不同时间尺度上协同运作。
为此,智平方最新发布了类脑具身智能系统NeuroVLA,借鉴人脑皮层—小脑—脊髓三级机制,构建了全球首个三级类脑架构:皮层负责语义理解与任务规划,小脑负责高频运动协调与动态修正,脊髓负责毫秒级运动执行与安全反射。这一设计让机器人首次具备了类似生物系统的层级智能能力,从架构层面提升机器人在真实物理世界中的稳定性、实时性与能效。实验结果显示,NeuroVLA能够将机器人运动抖动降低75%以上,在碰撞发生后20毫秒内完成反射响应,同时显著降低系统功耗。
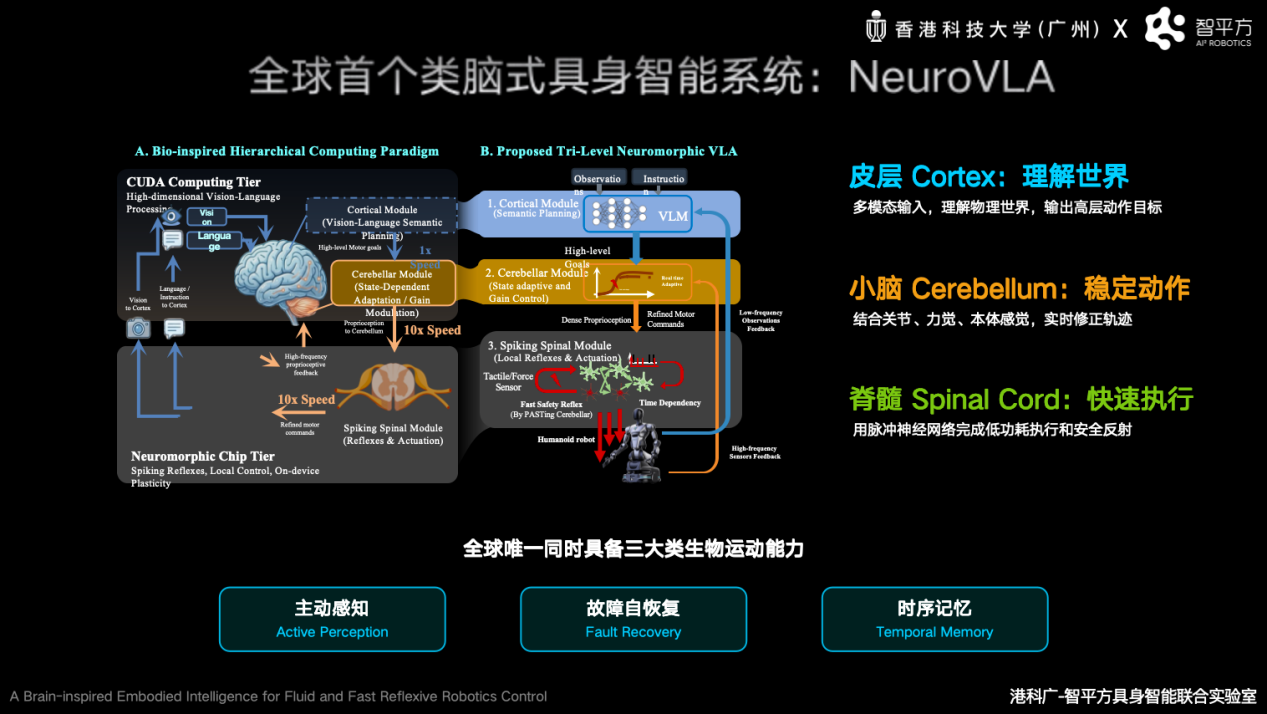
从端到端VLA,到融合世界模型的Video2Act,再到类脑NeuroVLA,郭彦东在智源大会上勾勒出一条清晰的机器人大脑进化路线。从“会推理”走向“会本能反应”,未来的机器人或将越来越接近真正的人类智能。
(本文图片由受访单位提供)